Tour
Features
Languages
Pricing
Blog
Docs
FREE Trial
LOGIN
Tour
Features
Languages
Pricing
Blog
Docs
FREE Trial
LOGIN
Get Started
Search
Search
Airbrake Blog
Discover the latest Airbrake product updates, announcements, and articles
Content Title
Description
Search
Search
How to Leverage Iterative Testing to Build Better Software
SDLC
What is Prompt Engineering?
Software Development
Comparing Popular Web Stacks: MERN, MEAN, MEVN, MENG, LAMP, and Ruby on Rails
Software Development
New Pybrake Framework Packages Are Here
Airbrake News
Check Out These New Gobrake Framework Packages
Airbrake News
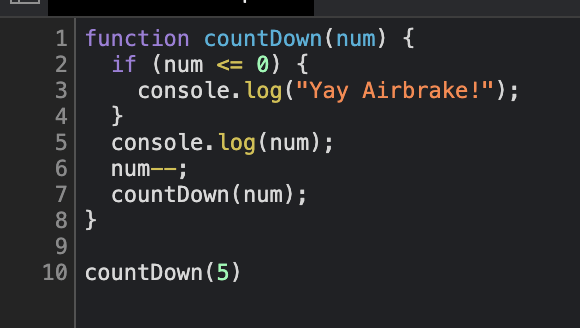
JavaScript Error: Maximum Call Stack Size Exceeded
Airbrake Performance Monitoring for Java Is Finally Here
Airbrake News
How To Improve Your Apdex Score
Why Ruby on Rails Works For Machine Learning Development
A Guide for Developers Searching for Their Next Job
Software Development
First
Prev
1
2
3
4
5
Next
Last
Posts by Tag
DevOps
(21)
Software Development
(8)
Airbrake News
(4)
SDLC
(3)
fearless deployments
(3)
Debugging
(2)
Featured
(2)
Airbrake
(1)
Awesome Airbrakers
(1)
Finance
(1)
ssl
(1)
tls
(1)
See all